KINDLY NOTE
This was a corporate project that I worked on. I was brought onboard once the product had been built and when the team was past the initial research and ideation phase. Owing to this, some salient aspects of the design process have been omitted in the approach section.
— TEAMMATES
Paritosh Chhibber
Nitika Pandey
Rajesh Sharma
Abhilekh Choudhary
Sumit Maingi
Amol Hadkar
Jayesh Motwani
— MY ROLE
UI/ UX Designer
Product Manager
— TOOLS USED
Design:
Balsamiq, Sketch, Figma, InVision
Project Management:
Jira Software, Confluence
Tech Stack:
Node.js, TypeScript, Polymer, Docker, Kubernetes, Jenkins, MongoDB, Redis, Elasticsearch, RabbitMQ, MinIO, Microsoft SQL Server, MySQL, ORACLE, PostgreSQL, IBM DB2, HELM, Kibana, Swagger, AWS- Serverless, EKS, CodeBuild, Lambda, CloudFront, RDS, CloudWatch, DynamoDB, S3, API Gateway, Kinesis Firehose
THE CHALLENGE
Large firms have a lot of data but seldom know how to manage it effectively. With countries across the globe enacting laws and regulations for the protection of personal data, it is imperative organisations abide by them. But where do they start? The firms have a lot of data that isn't organised but can be catalogued into an inventory. The inventory should be accurate, based on real data, and complete. Inventories can be of physical or logical assets– the latter is harder but more useful to catalogue. Such a catalogue or inventory would be an organised asset that could help it become GDPR compliant.
THE SOLUTION
Build a system that connects to an enterprise that consists of wide data sources, facilitates their automated scanning, creates and maintains an accurate inventory of logical data assets in the enterprise, facilitates risk assessment, and traces data lineage flows- thus not only enabling data transparency but also solidifying data governance and management.
THE APPROACH
Engage
Partnering at a deep level, taking full ownership of the product along the senior stakeholders at Global IDs. Our detailed solutions, domain guidance from their management, in a truly collaborative fashion made for a holistic deep engagement.

Collaborate
Following a dual track agile workflow & working as a distributed team with stakeholders across the US, development teams in Kolkata & ourselves in Pune, we architected an enterprise solution, executing quality in record time.

Brand
We understood the spirit of the product well along with senior stakeholders, collaboratively conceptualising it. Given our deep understanding of the ecosystem in which it existed, it made sense that we played a key role behind the core identity of MDB. Brining in the name ‘Make Data Better’, a logo which captured the spirit & essence of the product.

Design
We called our customers daily (and frequently their customers– end users), rapidly prototyped design iterations and consistently reviewed them for richer feedback. Constantly validating what was valuable before jumping to the best way to build it.

Engineer
A portable solution using Kubernetes, Docker, MEAN stack, RabbitMQ, Redis automated backups & restorations, scripts for various customer and installs on-prem across various versions of RHEL & Cent OS. These came together to work as a hybrid system with machine learning on the cloud & data processing on-premises: a perfect mix of security, performance and reliability.

MY CONTRIBUTION
I wore multiple hats during my time on the Global IDs project. My role mediated between understanding and jotting down client requirements by getting on calls with them and sometimes our end users. I conceptualised new features by mocking up wireframes and then coordinated with stakeholders to review them before moving on to visual designs. Additionally, I also implemented product backlogs by writing multiple user stories and acceptance criteria for the development team.
Final Design Outcome
drag the slider below!

the opportunity area
ORGANISATIONS + NEED +INSIGHT
organisations: that want to comply with GDPR laws
need: a systematic methodical approach
insight: to attain data transparency via data curation
Users of Enterprise Applications such as Information Architects, Data Stewards and Application Owners require transparency in the data that lies within their system.
This is how we derived value from the data.
This is how we profiled, cataloged and classified the data.
This is how we made data better.
⬇️
Behold, this is Dual Track Agile

• Discovery and Delivery sprints ran in parallel.
• Enabled the entire team to get involved in both the discovery aspect and the development aspect of the product development.
• Validations and insights from the Discovery track served as a guide for the Delivery track- instead of blindly developing new features that users might or might not need or want, we made sure that every element validated in the Discovery track was actually needed and would bring value to the users.
• Because every aspect of the product was validated in the discovery track and further tested on users, no unnecessary or unwanted features or elements needed to be developed and added to the product. This not only resulted in a better user experience but also streamlined the way the product was designed and developed.
Brace yourself for Seamless Data Discovery & Curation
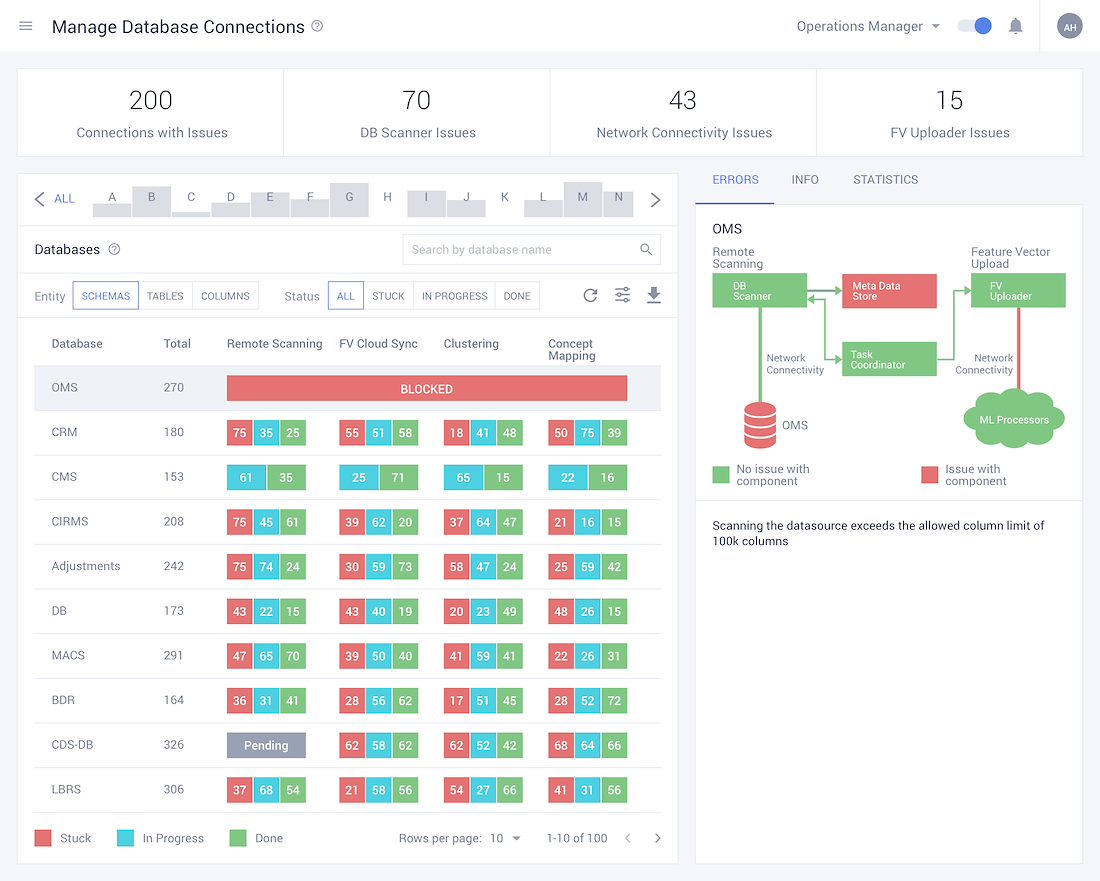
• Every large corporation has multiple verticals, with each of them having their own custom database. These databases in term house 'n' number of data columns. Humanely, it is not possible for anyone to remember which database contains what data. This is where the magic of discover unravels.
• Discover is a data source connection that identifies individual data points (could be anything really, an Email ID, SSN, etc) in the data store by connecting to the database on the customers end.
• Using Machine Learning, the system then moves on to Curate these data points. This step breaks down and classifies the data points into entities and concepts.
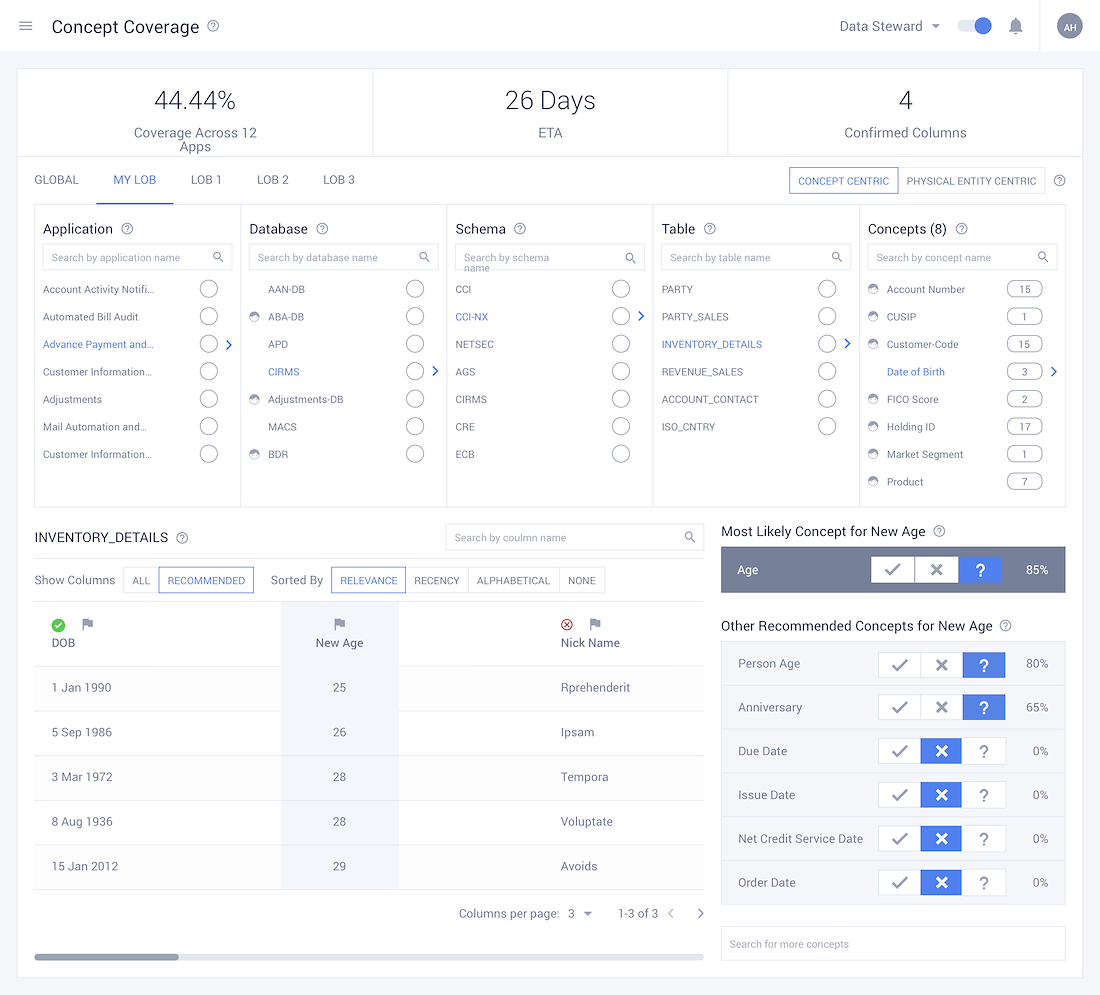
Gear up with Assiduous Data Organisation
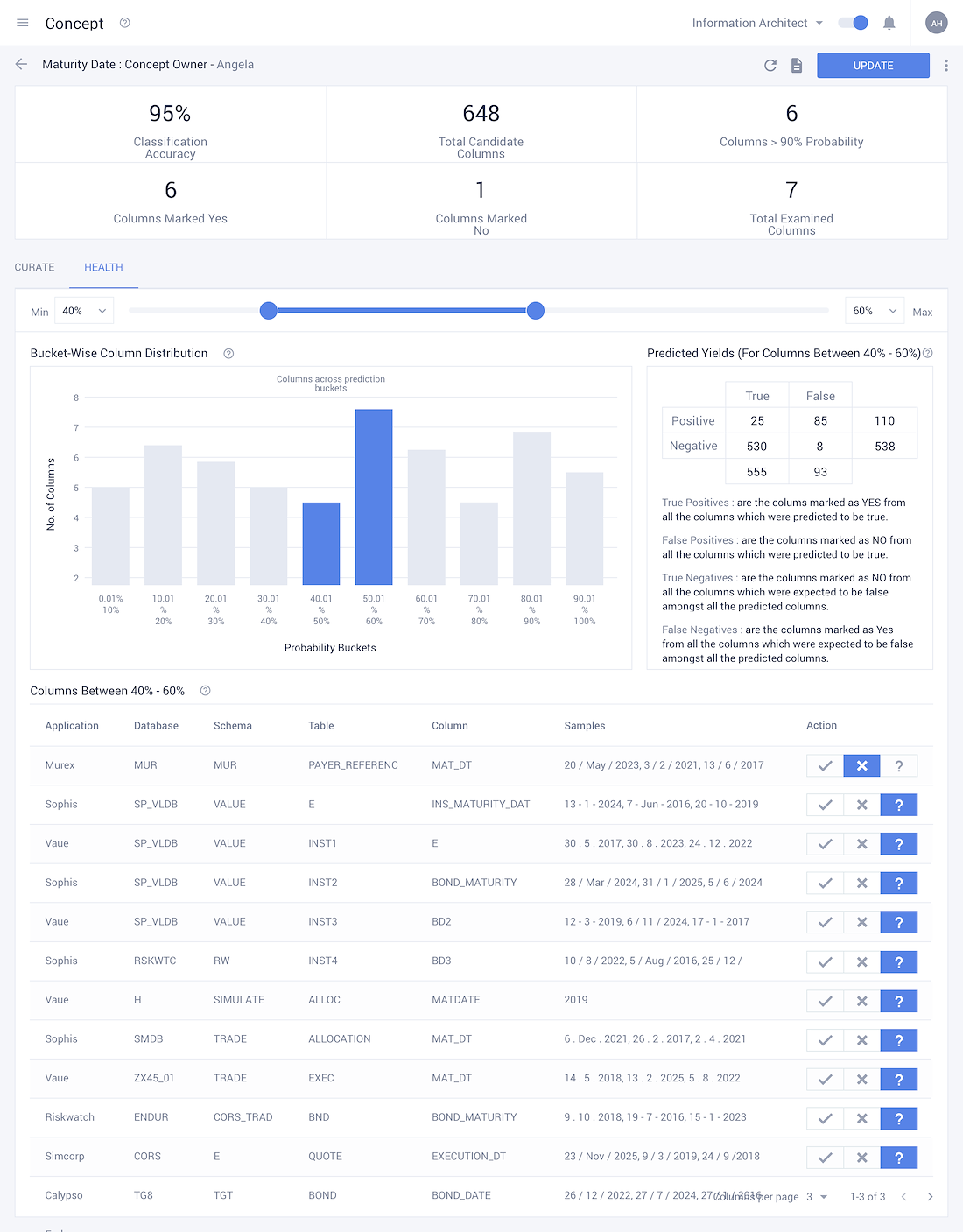
- • The only manual intervention required for classifying data comes during the initial step of data classification, where the Information Architect must mark few data points as samples.
- • With the data points marked, the ML algorithm classifies them into concepts and entities
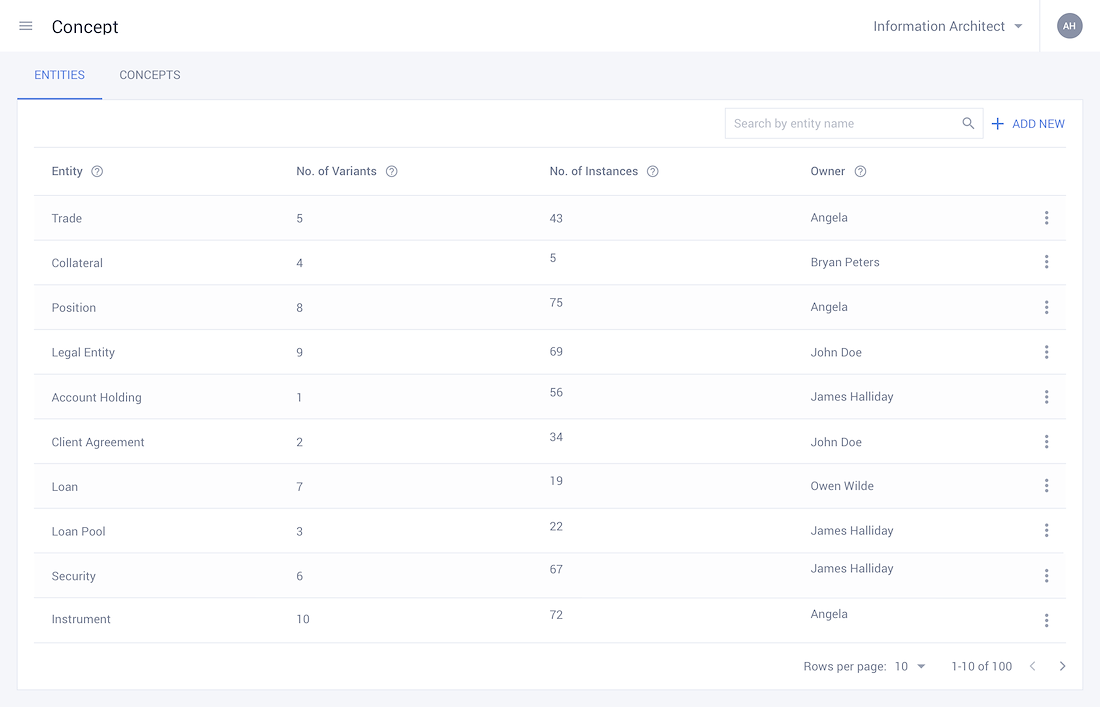
• Each entity has its own respective variants and instances in the system, which are all jotted down by the system, allowing for greater transparency into the data housed within the organisation.
• Classification accuracies depict the level of confidence in the ML algorithm for marking various concepts. A low accuracy would prompt the Information Architect to intervene in order to improve this classification.
Marvel at Robust Data Security & Compliances
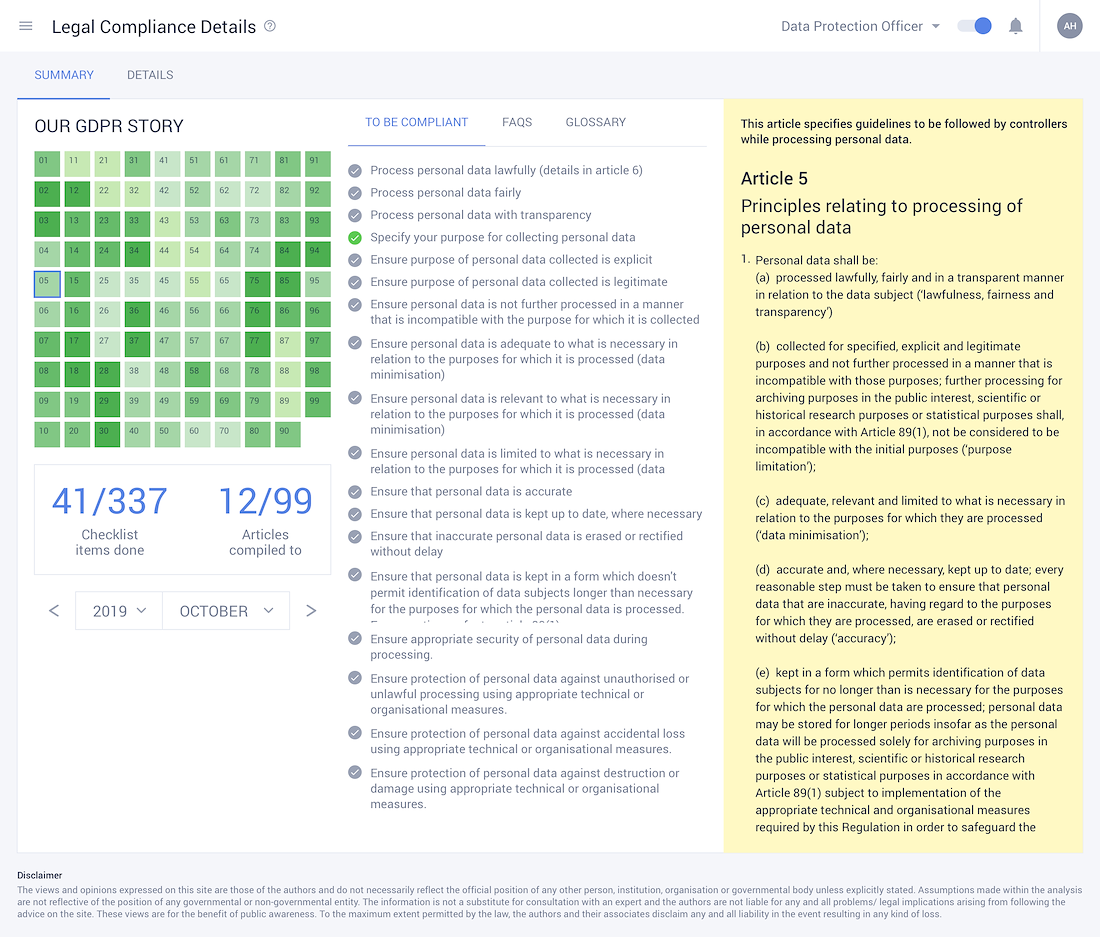
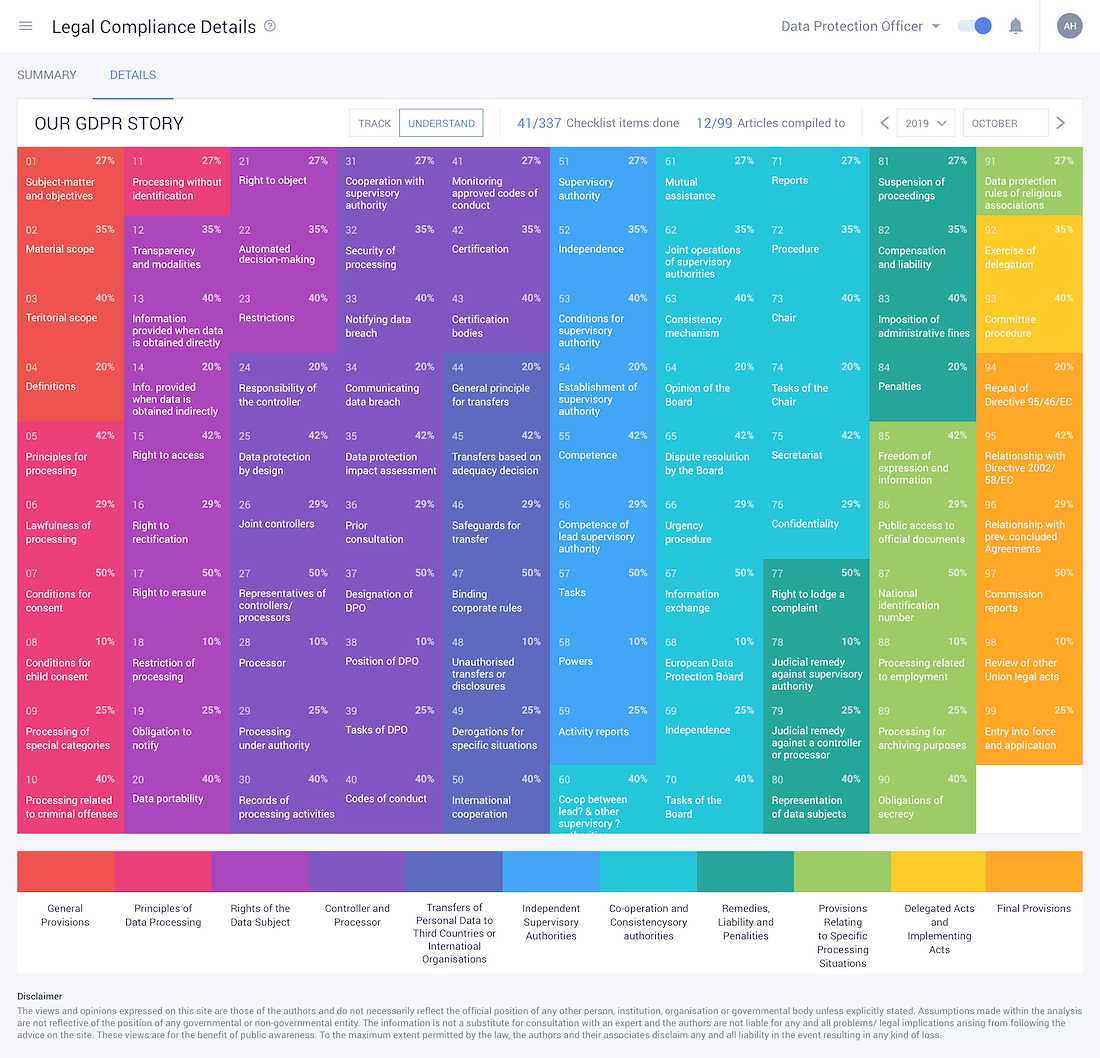
- • Crosscheck legalities and GDPR compliances within the systems extensive GDPR documentation.
Meticulously Pinpoint the Flow of Data across the organisation
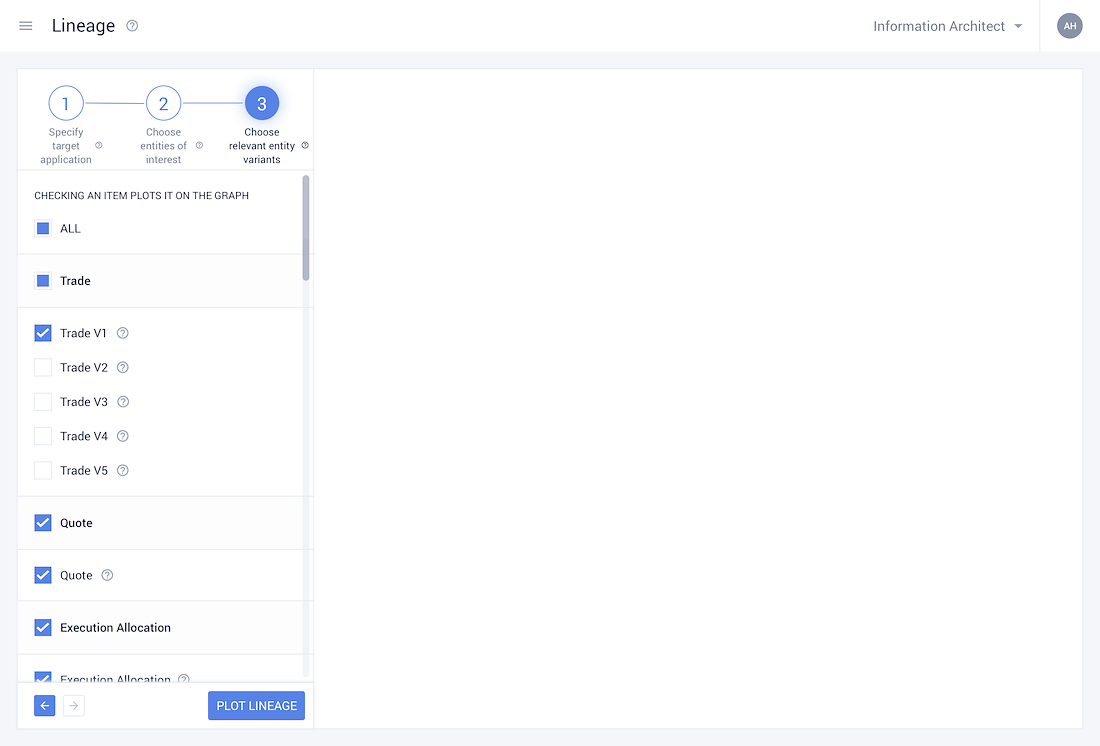
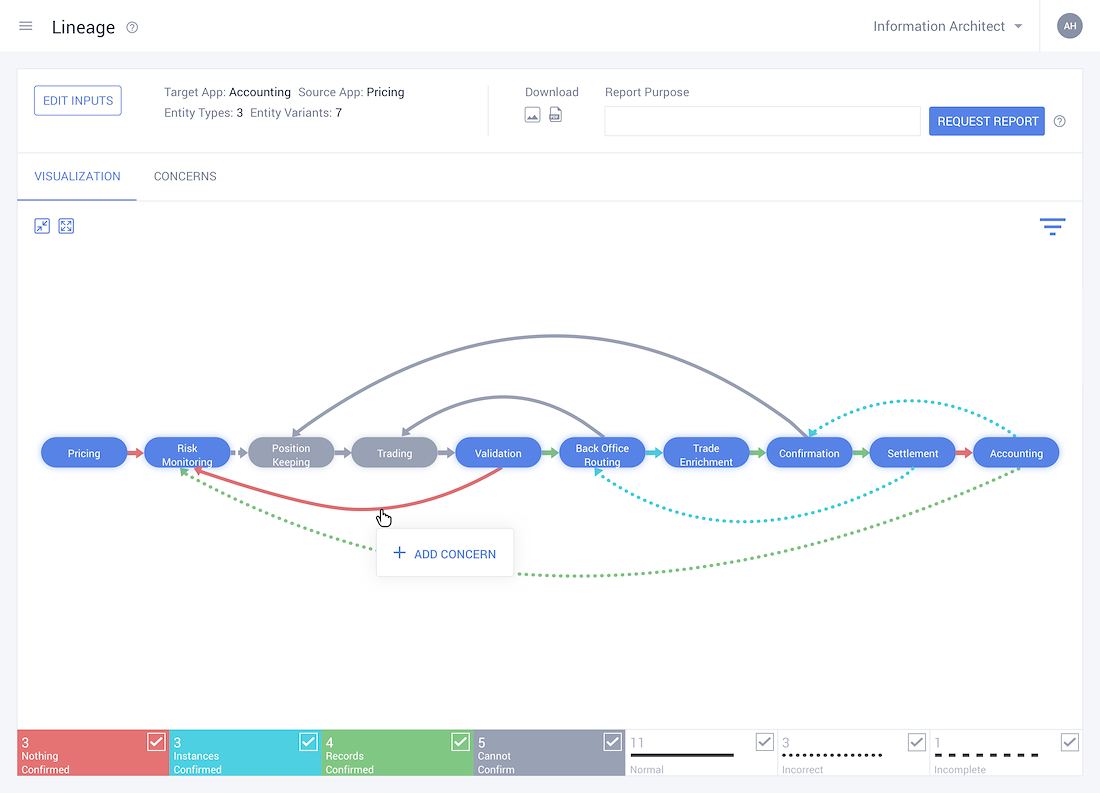
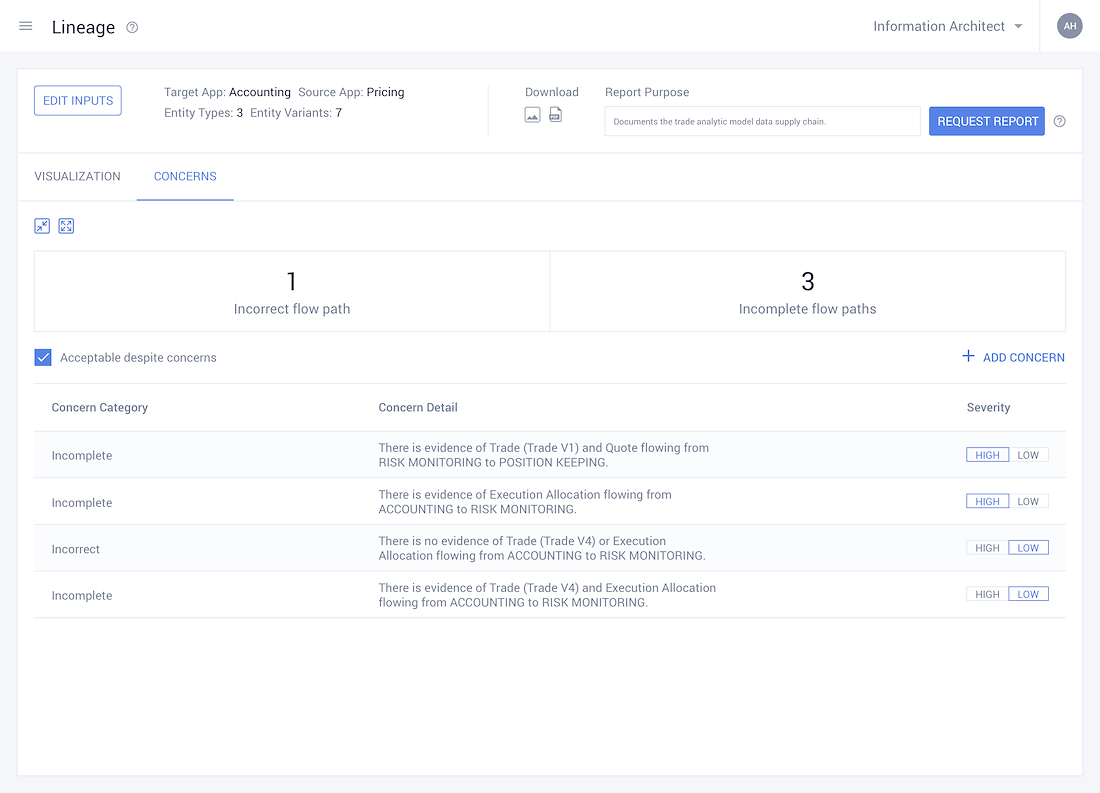
- • Track how data flows through the organisation and is subsequently managed. For example:- your Gmail ID is not only used to access your mails but extensively across the Google Suite. Multiple Google products use it as a data point. As this data concept flows through the organisation and is used by different business process, the way that is is managed also changes.
• With this data flowing over multiple organisational boundaries, documentation tracking its usage is imperative.
• Logically figuring out how the data flow in the system looks.
• It allows the user to gauge their entire data landscape at a high level, assisting them in understanding how data flows.
Effortlessly Generate GDPR Reports

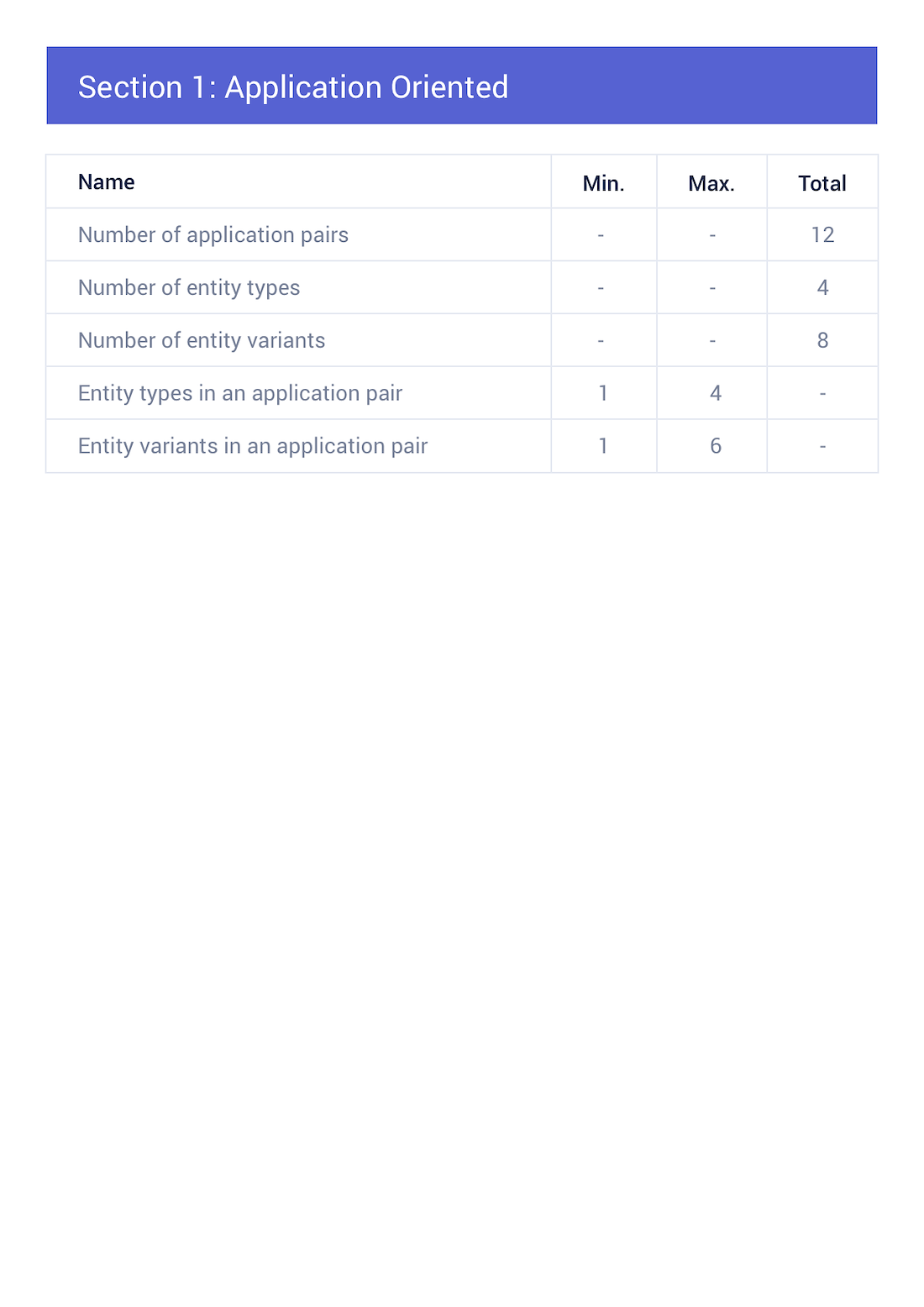
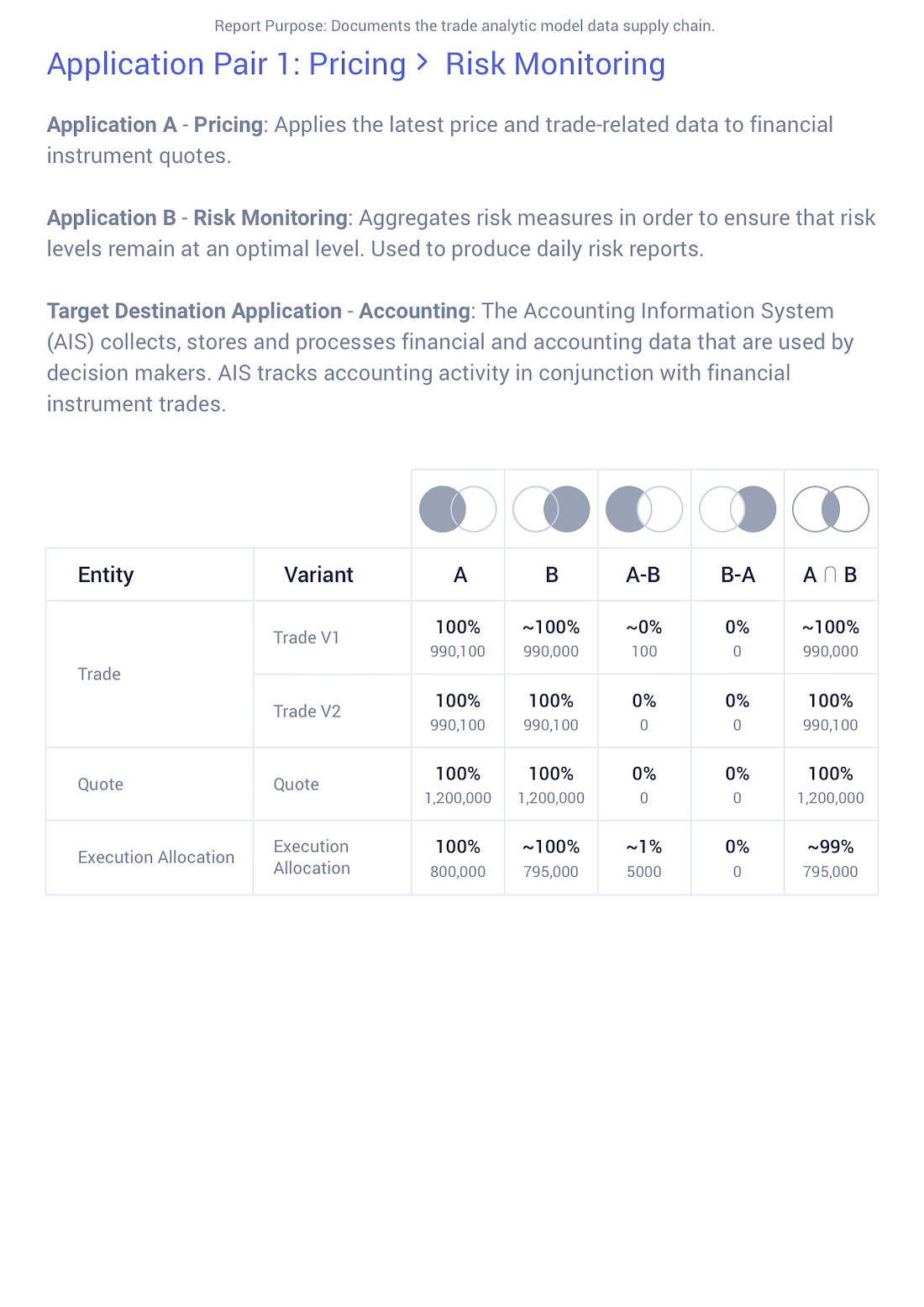
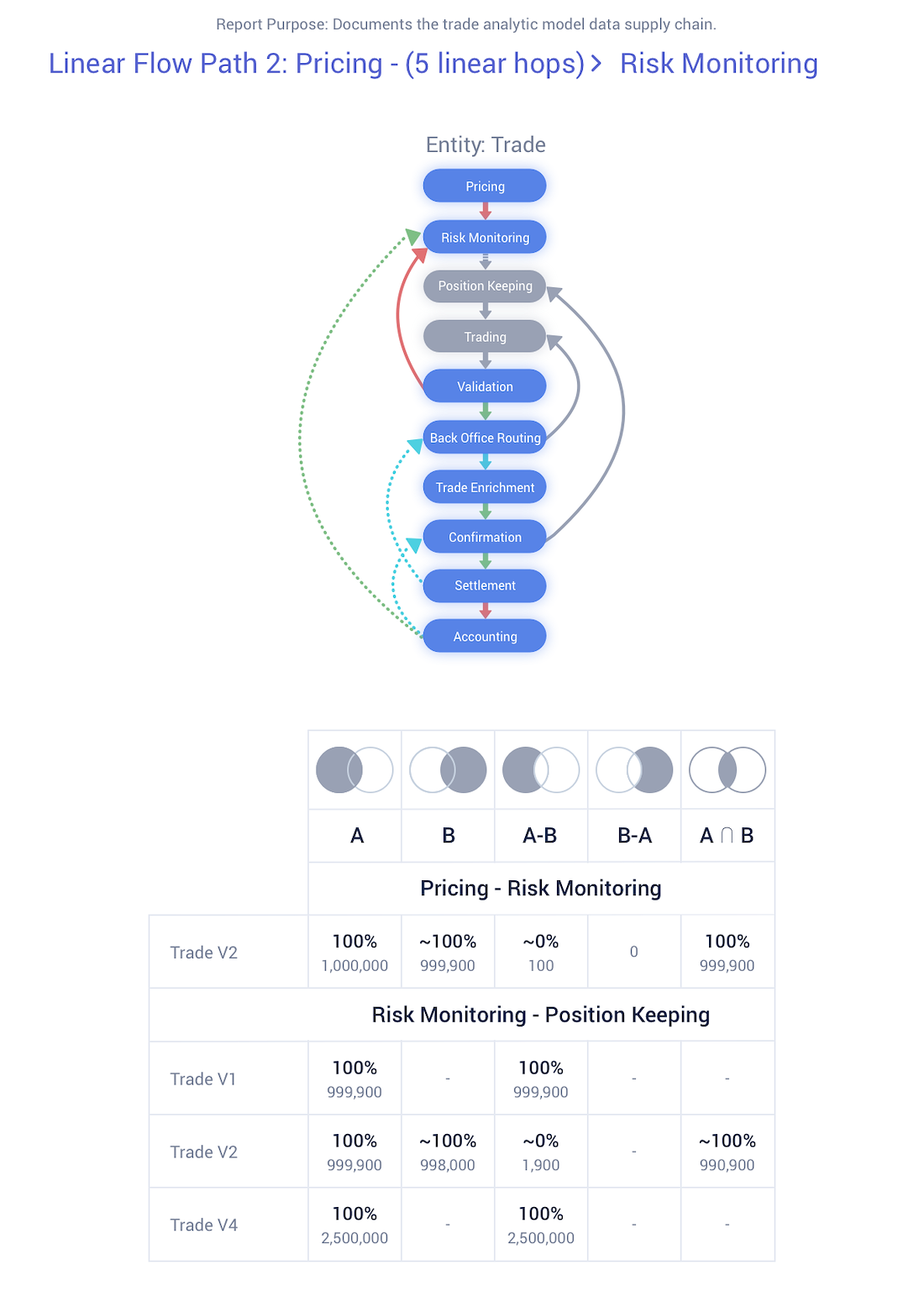
- • By far, the most valuable byproduct of the MDB software!
- • The Data Lineage Report is a comprehensive document of all the various data concepts and their respective flows across the organisation.
• Encompasses all lineage flows of the entity and its subsequent variants that have been requested by the user.
• GDPR compliance documentation at its finest.
Key Takeaways
'Vigilantibus Et Non Dormientibus Jura Subveniunt'
- The law assists those who are vigilant and not those that sleep over their rights.
GDPR is the torchbearer for robust data protection laws that ensure power to the people. The exorbitant penalty for non compliance of these laws has acted as an immensely powerful precursor for multiple companies to adhere to these new standards. However, given the boundless and labyrinthine structure of the data landscape, most organisations do not know where to start. The MDB product seeks to alleviate this issue amongst many others. And, if you are a data subject, I urge you to exercise your right and make the most of this regulation.